PeerDirect / GPUDirectについての振り返り
弊社のブログ記事を改めて見直してみたところ、GPUDirect™に関する記事がありませんでしたので、旧Mellanox(現Nvidia Networking Business Unit)では、PeerDirectとして総称されていた、GPUDirect™ について改めて振り返ってみたいと思います。
同社における、GPUDirectの定義は、「メインメモリを一次的なストレージとして使用したり、データ移動にCPUを活用することなくPCIeデバイス間で直接データを転送するもの」でありました。この歴史は割と長く、2009年のNvidia社とメラノックスによる共同開発の発表より始まっています。また、「GPUDirect」自体は、Nvidia社の商標であり、同社では、GPUDirect の機能をWindows環境で活用したり、ビデオ転送に用いたりとしていますが、本記事内で触れるのは、旧Mellanoxが、かかわったとされる部分についてのみとさせていただきます。
■ GPUDirect 1.0
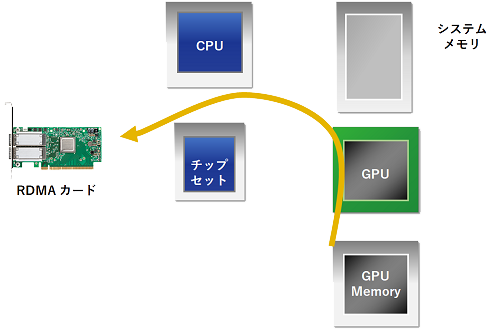
GPUメモリ上のデータをHCA を介し他ノードに転送する場合、GPUDirectがない場合には、
- GPUは、GPUメモリからGPUの管理下にあるシステムメモリのデータバッファ[1]にデータを書き込みます。
- ホストCPUは、GPUの管理下のデータバッファ[1] から、HCAの管理下にある、システムメモリのデータバッファ[2]にデータをコピーします。
- HCAは、システムメモリのデータバッファ[2]からデータを読み取り、リモートノードにデータを転送します。
GPUDirect 1.0 では、メモリの管理主体がそれぞれ異なるために発生していた上記2. の工程を、共通のAPIを設けバッファの共有を可能にするためのKernelパッチを提供することで、排除致しました。この時点においては、GPUDirect 専用のMLNX OFED ドライバパッケージが提供されていました。
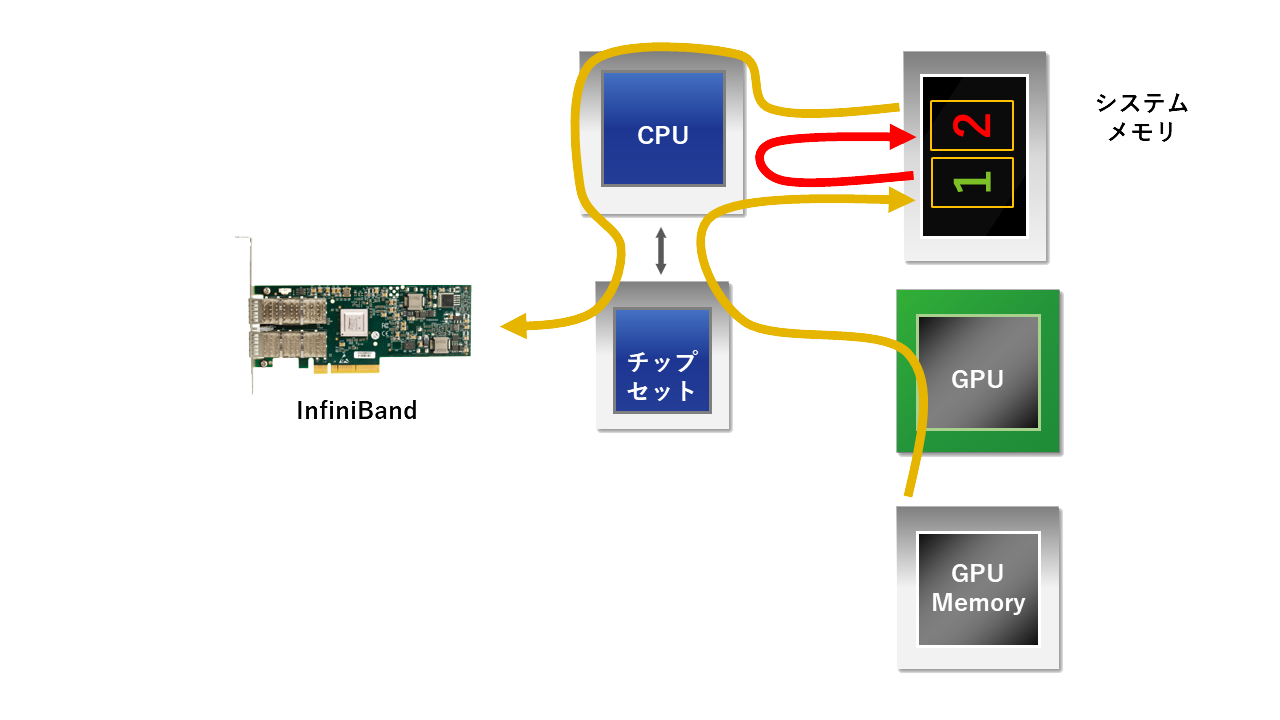

このGPUDirect 1.0によりGPU通信においてのCPUの関与とバッファー間コピーの必要性により生じていたシステムボトルネックが緩和されることになりました。当時の製品ブローシャによる説明では、GPU間の通信時間が30%削減されたとありました。
■ GPUDirect RDMA
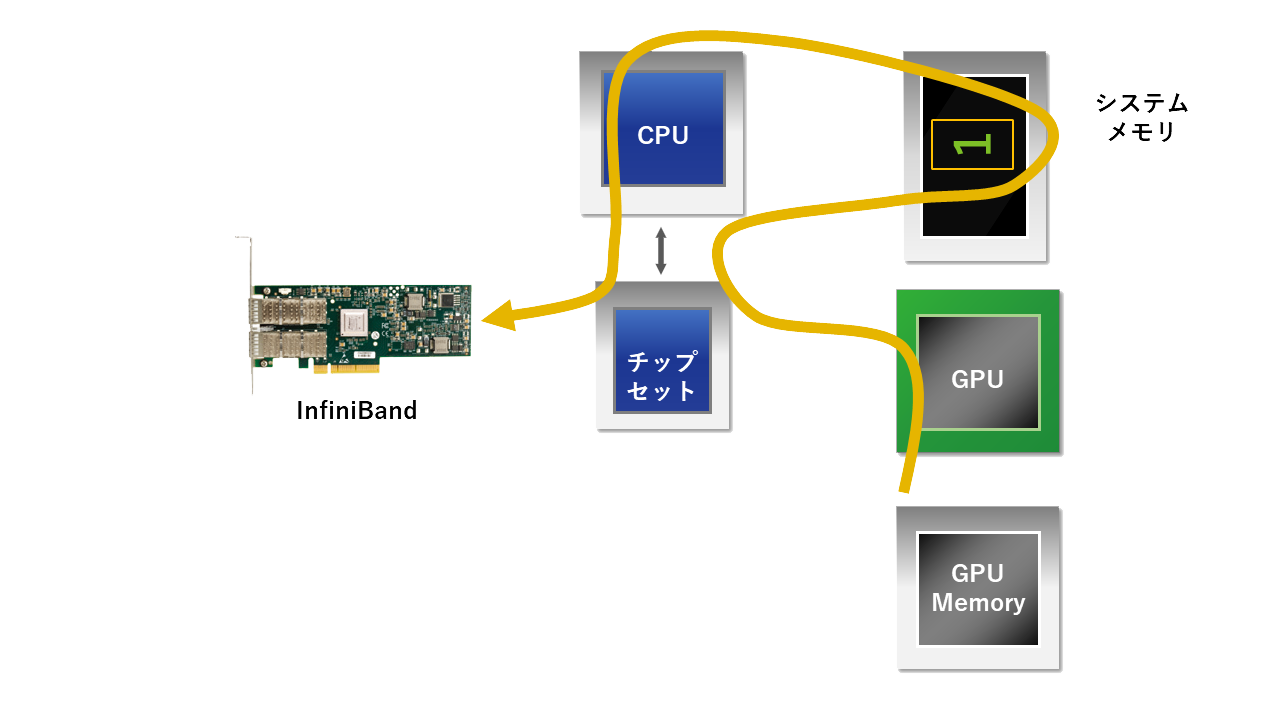
バッファを共有することでメモリ間コピーを減らす上記 GPUDirect 1.0 の方法では、本来GPUメモリに格納されているデータを一旦、システムメモリのデータバッファーにコピーしていることに変わりはなく、またそれではゼロコピーが身上のRDMA(Remote Direct Memory Access)では、真の意味でのRDMA転送になりえません。それを解消し、遅延性能をさらに向上させるため、CPUが、GPUタスクとデータ転送の間の同期を取り、また、RDMA対応カードが、直接GPUメモリにアクセスできるようにしました。これにより、GPUDirect RDMAでは、以下の図のように、GPUメモリから外部ノードへの直接のDMA転送を可能にしています。
Mellanoxでは、標準のドライバパッケージである、Mellanox OFED 2.1-1.0.0において、新たにPeerDirectのサポートを追加いたしました。PeerDirectは、GPUDirect RDMA だけをサポートするのではなく当時話題であったXeon Phiといったカードにも対応すべく抽象化を行い、またGPUなどの「ピアメモリクライアント」とIB CORE間のAPIを活用し、データバッファ―のピアメモリの読み書きを可能に致しました(共有するGPUバッファの読み書きを可能にしました)。またこの時期よりLinuxのカーネル自体もGPUDirect(異なるドライバ間でのメモリ共有)に対応し、カーネルへの個別の追加パッチは不要になっています。
■ 動作環境:
● ハードウェア:
- Mellanox ConnectX®-3 VPI/EN 以降のRDMAカード(RoCE 環境でも動作)
- NVIDIA® Tesla™ / Quadro K-シリーズ あるいは、 Tesla™ / Quadro™ P-シリーズ GPU
● ソフトウェア:
- MLNX_OFED v2.1-x.x.x 以降(カードによって対応するOFEDのバージョンが異なります。)
www.mellanox.com -> Products -> Software – > InfiniBand/VPI Drivers -> Linux SW/Drivers - GPUDirect RDMA プラグインモジュール:www.mellanox.com -> Products -> Software – > InfiniBand/VPI Drivers -> GPUDirect RDMA (左のナビゲーションペイン上)
- NVIDIA ドライバ http://www.nvidia.com/Download/index.aspx?lang=en-us
- NVIDIA CUDA ランタイムとツールキット https://developer.nvidia.com/cuda-downloads
- NVIDIA ドキュメント http://docs.nvidia.com/cuda/index.html#getting-started-guides
- 対応MPIライブラリ:Mellanox HPC-X、Open MPI、MVAPICH2-GDR、SpectrumMPI
一旦動作環境を構築してしまえば、GPUDirect RDMAは、プログラム・コードに変更を加えることなく、活用可能であることより、比較的容易に利用可能なソリューションです。
また、x86アーキテクチャ上だけではなく、Power8/9といった、他のCPUアーキテクチャをサポートするなど、その動作範囲は広がっています。
■ PeerDirect Async
さて、「GPUDirect RDMA」において、データの転送フローにRDMAが活用されることとなり、転送経路においての冗長な部分はなくなりました。また、転送自体、ハードウェアで行うRDMA転送となりますので、CPUが関与することはございません。しかしながら、引き続きCPUは、GPU側とCPU側の両方の計算、通信、同期操作の管理を担当しており、たとえば、GPU側の計算の結果がリモート宛先に転送される場合、CPUはGPU計算の完了時に同期して、通信操作を発行する必要があります。 そのため、転送自体にかかわらずとも、同期の待機の為にCPUサイクルと多大なCPUパワーの両方が消費されていました。
これを解消するのが、「GPUDirect Async」メラノックスでいう、「PeerDirect Async」となります。敢えて、別名で「PeerDirect Async」と記載している様に、GPUの他、FPGA、ストレージコントローラなど同格のPCIe機器からネットワークカードを制御することにも視野に入れているようですが、現状は、Nvidia GPUにむけて構成されています。GPU側で、GPU計算の完了に伴い、RDMA 転送のスタートをかけることを行うことで、計算、通信、同期操作の管理からCPUを解放いたします。
■ 動作環境:
- 前提条件:nvidia_peer_memorydriver、GDRcopy1library
- GPUDIRECT ASYNC OVER OFA VERBS
- CUDA 8.0+ Stream Memory Operations (MemOps) APIs
- MLNX OFED 4.0+ Peer-Direct AsyncVerbs APIs
- 対応するMPIライブラリ:MVAPICH2-GDS(実験的なサポートとして、2017年頃より提供されています )
■ 2019-:
では、GPUDirect は、今後どうなっていくのかという点について、2019年11月にNvidiaのプレスリリースで マルチ GPU/マルチノードのネットワークおよびストレージ IO 最適化スタックNVIDIA MAGNUM IOソフトウェアスイートが発表されています。この中の中核技術としてGPUDirect が挙げられており、旧Mellanoxを含めた、ネットワークおよびストレージの業界のリーダー企業と緊密に連係して、Magnum IO を開発とあります。Nvidia においては、GPUDirectに関する技術は、ビデオ、ストレージ、など様々に展開しており、必ずしも旧Mellanox と共に開発した上記の部分だけではないのかもしれませんが、GTC2020の基調講演でも触れられており、引き続きNVIDIAAIやハイパフォーマンスコンピューティングの中核的な技術として活用されていくのではないかと思われます。
また、先週開催されたOFA(OpenFabrics Alliance)のVirtual Workshopにおいて、すぐに使えるものではありませんがIntel社がDMA-BUFと呼ぶ技術について講演しております。現時点、GPUDirect RDMAが、Mellanox OFEDに依存している点を突いたものであり、対抗する技術が出てくることで今後さらに業界的には注目が高まるのではないかと思われます。
本ページに記載されている会社名、会社ロゴ、商品名は、各社の商標または登録商標です。本ページに記載されているシステム名、製品名などには必ずしも商標表示(TM、®)を付記していません。