シリーズ・コラム(第四回)LIQID CDIユースケース #3:このジョブGPU何枚必要?

シリーズ・コラム第四回、LIQID CDIユースケース紹介第三弾
LIQID CDIは、PCIeデバイスであればどのようなものでも対象とする製品だが、昨今はAIブームの影響か「GPUオンデマンド」というキャッチフレーズでマーケティングすることが多い。
「GPUオンデマンド」とは、「プール化したGPUから、必要な時に必要な数のGPUを用いてベアメタルサーバーを構成し、使い終わったらプールに戻し他のユーザーに開放する」というコンセプトだ。LIQID CDIはこの字句で定義していることをその通りに実現できる。今回のコラムでは、このCDIの価値を役立てていただいている典型的なユースケースを紹介したい。
ジョブ処理に必要なGPU台数
LIQID CDIが解決した課題は「これから走らせようとしているジョブが果たして何枚のGPUを必要とするか事前に判明しない」というものだ。
このAI開発ユーザーが抱えていた課題はこうだ。GPUを搭載しているサーバーでジョブを実行したが、性能不足がわかりGPUを追加しなければならないことが判明した。幸いにも別のサーバーに使用可能なGPUがあったのでそれを物理的に移設して、無事に懸案のジョブを実行することができた。
結果オーライのように見えるが、経営者はそう考えなかった。同様のことが多発していたし、そもそもジョブ処理の度にこのような作業を行うのは極めて効率が悪いし、物理的にGPUを移設する回数が増えれば、ハンドリングミスによって高価なGPUをダメージしかねない。もっとサーバーとGPUを柔軟にミックスでき効率的に利用できるシステムはないのだろうか?そう考えて出会ったのがLIQID CDIであった。
導入したシステム構成は以下の通り(モデル情報は割愛)。
- 1U サーバー x 16台
- GPU x 30枚
- LIQID CDI x 1
従来のシステムではGPUはすべてサーバー筐体内部に搭載されており、そのGPUを他のサーバーで使用するためには移設するしかなかった。新システムは、前出のGPUオンデマンドのコンセプトをそのまま具現化したようなシステムであり、サーバーにGPUを搭載する必要はない。そのため、採用したサーバーは廉価な1Uサーバー 16台であり、これらサーバーが動的に共用するための30台のGPUプールである。ジョブ実行時にGPU不足が判明した場合は、GPUプールから使用可能なGPUを選び、管理ソフトMatrixのGUIのクリック一つでベアメタルサーバーに追加可能だ。もちろんGPUを追加する場合だけでなく、逆に余剰が判明したGPUはプールに戻し他のサーバーに割り当てることもできる。このユースケースのLIQID CDIシステムは、経営者が望んだとおりの「ハードウェアを最大限に活用でき、フレキシブルかつリアルタイムで動的再構成できるシステム」そのものとなった。

LIQID CDIのマルチベンダーGPUサポート
この典型的なGPUオンデマンド・システムだが、導入するGPUが単一のメーカー・モデルでなくても使用できる。更に言えば、今後のAI開発、とりわけ推論(Inference)フェーズでは、GPUだけではなく各社が開発を進めているAI専用プロセッサの採用も考えられるが、LIQID CDIはそのような要件にも対応可能だ。下図のように、複数のメーカーの異なるPCIeカードを同時にプール化することができる(一部ホストの制限により完全なAny to anyではない)。
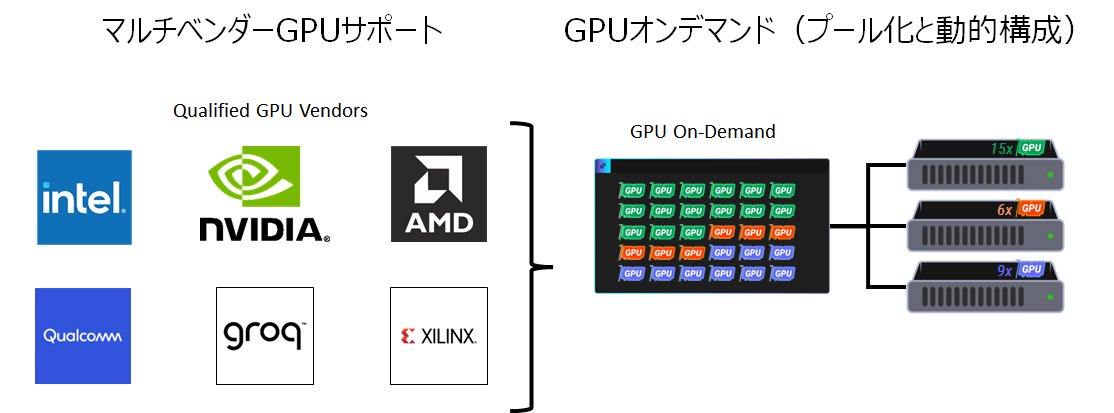
今回は「GPUオンデマンドの典型的なユースケース」を紹介した。一般的に、ハードウェア投資は複数年での償却を想定するが、これだけ技術の進化が激しいと今日調達したハードウェアが想定ライフをそのまま全うすることは難しいかもしれない。そのような不定の将来に備えて、柔軟性と効率性を提供するLIQID CDIでシステム設計するのはどうだろう。
これまで3回に渡りLIQID CDIのユースケースを紹介した。最終回となる次回は、LIQID CDIを導入した場合に期待できる経済効果、すなわちTCOの節減について触れたい。折角の機能や経済効果も、性能に満足できなければ画餅である。それらの懸念払拭にも努めたい。
(MF)